
Dit artikel verscheen oorspronkelijk op Frankwatching.nl.
Speciale leestekens – zoals een accent, trema of cedille – komen veel voor in het Nederlands. De meeste daarvan verschuilen zich in plaatsnamen en Franse leenwoorden (Curaçao, café en naïef). Omdat het online zoekgedrag van mensen vooral de incorrecte versie van dit soort woorden hanteert (die zónder leesteken), ontstaat er onder SEO-specialisten een dilemma.
Optimaliseer ik mijn SEO-content op basis van de correct- of incorrect gespelde versie van een woord?
Om antwoord te geven op die vraag, analyseer ik een videofragment van Google’s Search advocate John Mueller, uit de serie English Google SEO office-hours van 25 juni 2021. Naar aanleiding van zijn uitspraken, voerde ik bovendien zelf een onderzoek uit. De resultaten daarvan verbazen!
- John Muellers kijk op het gebruik van speciale leestekens
- Onderscheid tussen verschillend gespelde zoekopdrachten
- Klopt het wat Mueller zegt over SEO en leestekens?
- In de tussentijd…
- Het bewezen effect van leesteken-optimalisatie
- Nuances binnen de wereld van SEO
John Muellers kijk op het gebruik van speciale leestekens
In beginsel probeert Google haar zoekresultaten zoveel mogelijk op de zoekopdracht aan te laten sluiten. Typt een bezoeker bijvoorbeeld: ‘cafe in deventer’, dan zal de content (in theorie) in de meeste zoekresultaten ‘cafe in deventer’ bevatten (in plaats van café in deventer).
Aan de andere kant, zo beweert Mueller, probeert Google alternatieve schrijfwijzen van woorden te herkennen en ze zodoende als synoniem van het zoekwoord te erkennen. De verschillende zoekopdrachten leiden daarom tot erg vergelijkbare zoekresultaten, maar zullen niet exact hetzelfde zijn. Dat Mueller daar gelijk in heeft, bewijst de onderstaande afbeelding.
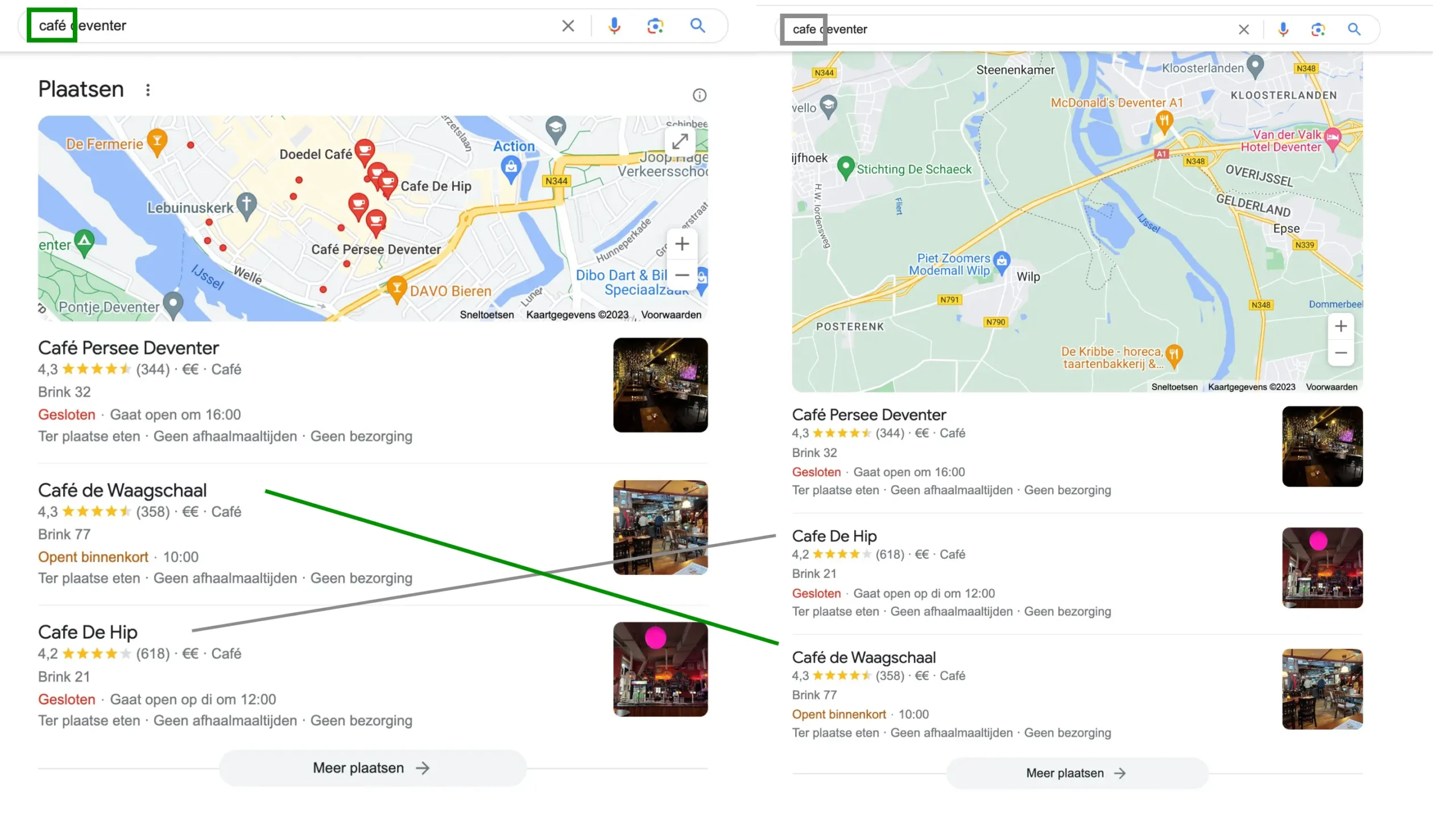
Onderscheid tussen verschillend gespelde zoekopdrachten
Google maakt in haar zoekresultaten dus onderscheid tussen verschillend gespelde versies van zoekopdrachten. Maar dat beantwoordt nog steeds mijn hoofdvraag niet: op basis van welke versie optimaliseer ik mijn SEO-content? Daarover vertelt Mueller het volgende.
“Over het algemeen raden we aan te focussen op de correct gespelde versie van het woord, want dit is de juiste, langetermijnversie van het woord. Maar als deze versie niet de ‘algemeen gebruikte’ versie is, is het niet problematisch om ook de algemeen gebruikte versie* in je content op te nemen. Als het typen van speciale leestekens iets is wat mensen gemiddeld minder doen, snijdt het hout om óók het woord zónder speciale leestekens te gebruiken.”
*Lees: versie met het hoogste zoekvolume.
Als je een landingspagina schrijft met de focus op het zoekwoord ‘café Deventer’, zou dit dus betekenen dat het woord café mét accent aigu de hoofdrol dient te vertolken op die pagina, terwijl je café ook zónder speciaal leesteken in de content opneemt – cafe dus.
Let wel, Muellers redevoering heeft betrekking op content met de focus op bedrijfs-, merk- en productnamen. Wellicht gaat zijn vervolg daarom niet op voor andere soorten content:
“Ik zou de focus echter niet verleggen naar de ‘populairdere’ versie van het woord, tenzij je jouw website en bedrijf wil rebranden. Want wat we in feite proberen, is de ‘officiële pagina’ voor dit product te herkennen. Het hernoemen van je product is iets wat onze systemen eerst moeten achterhalen en begrijpen. Door de alternatieve versie slechts óp te nemen in je content, is het voor ons een stuk makkelijker te herkennen dat bepaalde woorden bij elkaar horen en ze als (min of meer) synoniemen te erkennen.”
Klopt het wat Mueller zegt over SEO en leestekens?
Tsja, John Mueller is dé autoriteit op het gebied van SEO. Dat wil echter niet zeggen dat alles wat hij beweert, heilig is. Ik besloot daarom te testen of zijn uitspraken ook in de praktijk tot uiting komen.
Een transportbedrijf schreef ooit diverse landingspagina’s, waaronder:
- Dagelijks transport Servië
- Koeltransport Groot Brittannië
- Internationaal transport Slovenië
Google indexeerde de pagina’s en ze verschenen in de zoekresultaten. Op alle drie de pagina’s wordt consequent de correct gespelde versie van het land gebruikt – dus die mét speciaal leesteken (in dit geval een trema). De posities van de pagina’s binnen de zoekresultaten zijn afhankelijk van de ingetypte zoekopdracht. Zo vind je de pagina dagelijks transport Servië terug op plek vijf als je Servië mét trema schrijft, terwijl de pagina op plek elf verschijnt, wanneer je het trema niet gebruikt.
Zoals Mueller het ons voorschrijft, ging ik aan de slag met de optimalisatie van de drie landingspagina’s. Hier en daar verving ik de ë voor een e en deed dat minstens één keer in de headingstructuur van de pagina. Om het proces wat te versnellen liet ik Google Search Console de pagina’s opnieuw indexeren. Afwachten geblazen.
In de tussentijd…
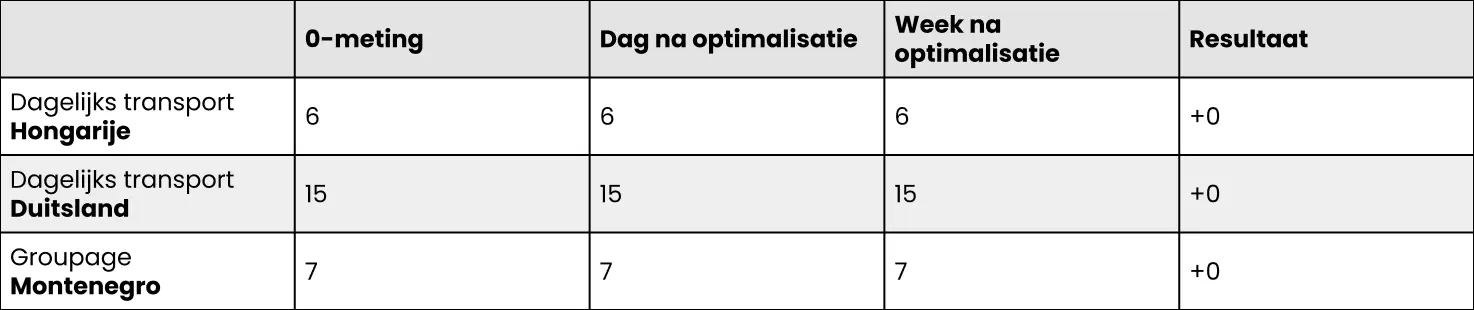
Zoals je wellicht weet, vindt Google het prettig als je een pagina ‘levend’ houdt – zeker als het gaat om content die niet tijdloos is. Zo erkent Google dat jouw pagina actueel – en zodoende relevant – is. Wijzigingen aan pagina’s leveren dan ook wel eens een kleine stijging in de zoekresultaten op. Om geen valse conclusies te trekken, optimaliseerde ik daarom ook (heel minimaal) drie andere landingspagina’s:
- Dagelijks transport Hongarije
- Dagelijks transport Duitsland
- Groupage Montenegro
Het bewezen effect van leesteken-optimalisatie
De resultaten van het onderzoek werden snel zichtbaar. Nog geen dag na de aangevraagde indexatie stond de pagina Dagelijks transport Servië bij zowel de correct als incorrect gespelde versie van de zoekopdracht op plek 3 (!). Ook uit de posities van de andere landingspagina’s bleek een aanzienlijke stijging. De posities van de overige (dus niet leesteken gerelateerde) geoptimaliseerde pagina’s bleven exact gelijk. Hieronder worden de resultaten in een tabel weergegeven.
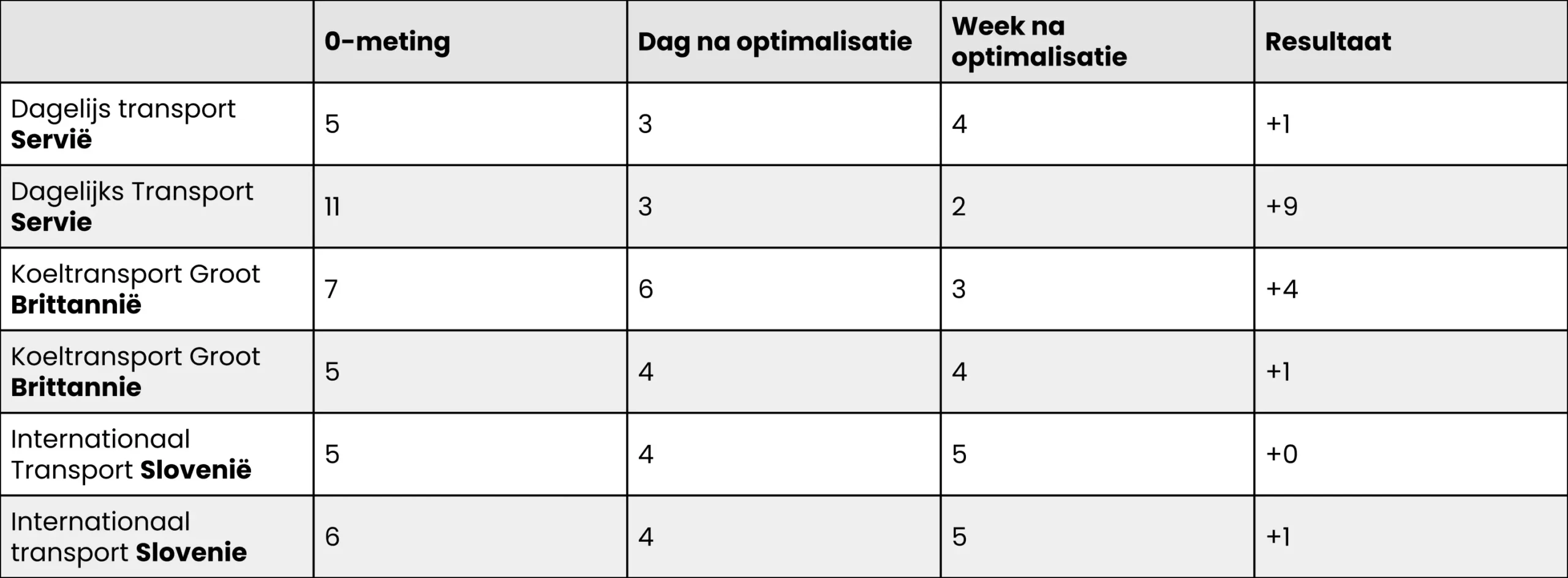
Wat opvalt is dat de landingspagina’s ook bij de correct gespelde zoekopdrachten op een hogere positie verschijnen dan voorheen.
Optimaliseer ik mijn SEO-content op basis van de correct of incorrect gespelde versie van een woord?
Omdat het positieve effect alleen opgaat voor de pagina’s die op leestekens zijn geoptimaliseerd, lijkt het er sterk op dat Mueller gelijk heeft. Dat betekent dat het antwoord op onze hamvraag als volgt luidt:
“Focus je in eerste instantie altijd op de correct gespelde versie van het woord, maar neem waar mogelijk ook de meest gebruikte versie van het woord op in je SEO-content.”
Nuances binnen de wereld van SEO
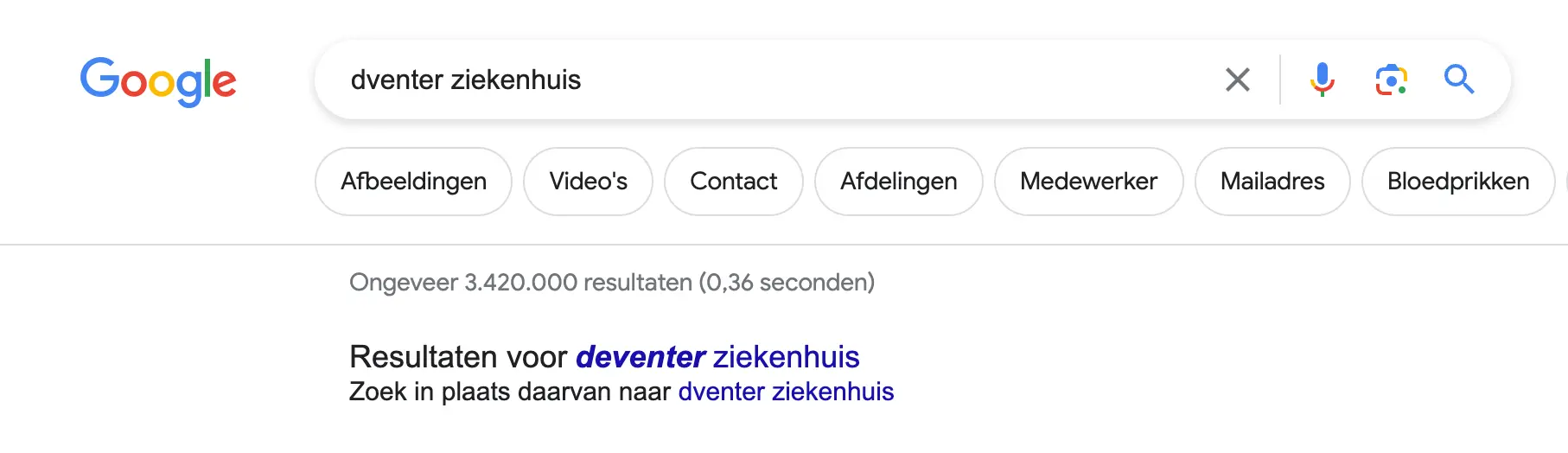
Enige nuance in een slecht vatbare kwestie als deze is altijd op z’n plek. Hoe duurzaam is dit antwoord bijvoorbeeld? Google beschikt immers over een spellingcorrectiesysteem, dat typ- en spelfouten herkent en automatisch voor de gebruiker corrigeert. Zoek je bijvoorbeeld naar ‘dventer ziekenhuis’, dan toont Google toch de resultaten voor ‘deventer ziekenhuis’.
Dit voorbeeld van spellingcorrectie heb ik op gedetailleerder niveau (namelijk dat van verkeerd gebruik van speciale leestekens) echter nog nooit ervaren. Ontwikkelt dit systeem zich daarentegen, dan wordt leesteken optimalisatie een stuk minder zinvol.
Daarnaast is de weging van leestekengebruik natuurlijk erg laag, als je deze wegzet tegen factoren als bijvoorbeeld domeinautoriteit. Zoek je op het moment van schrijven naar ‘cafe deventer’, dan vind je in de topposities genoeg sites terug die ‘café’ uitsluitend op de correct gespelde wijze gebruiken. Verwacht daarom niet de bol.com’s van deze wereld van hun troon te stoten, alleen door slim leestekengebruik.
Tot slot gaat leesteken-optimalisatie altijd gepaard met een bepaalde inconsistentie. En hoe professioneel kom je over als je woorden op eenzelfde pagina meerdere keren incorrect spelt? Dat zijn vragen om over na te denken…

Daan
SEO Specialist
Meer weten over dit onderwerp?
Neem dan contact op met Daan
Neem contact op
Inspirerende blogs

18 juli 2024
Wat is een anchortekst?
Lees meer
19 juni 2024
Wat is een canonical tag?
Lees meer
7 juni 2024
Wat is een sitemap?
Lees meer
27 mei 2024
De impact van longtail zoekwoorden
Lees meer
14 mei 2024
Wat is een alt-tag?
Lees meer
10 april 2024
Wat is een FAQ en wat zijn de voordelen?
Lees meer
2 april 2024
Hoe doe je een zoekwoordonderzoek voor SEO-doeleinden?
Lees meer
15 maart 2024
Wat kunnen we leren van Joost Klein en Europapa?
Lees meer
7 maart 2024